上海人工智能实验室发布以人为本的大模型评测体系,推动大模型实际应用
上海人工智能实验室发布以人为本的大模型评测体系,推动大模型实际应用
大模型的功能不断进步,评估得分也在不断上升,但人们对它的实际效果还是不太明白。在这种背景下,上海人工智能实验室提出的以人为本的评估方法,特别引起了人们的注意。此外,大型模型虽然得分较高,但实际能力却有所欠缺。但上海人工智能实验室的司南团队敢于突破,提出了以人为本的评估新法。以人为中心的评估体系与框架,让大型模型的测试更贴近人的需求,这对整个行业的发展起到了重要作用。
大模型的功能不断进步,评估得分也在不断上升,但人们对它的实际效果还是不太明白。在这种背景下,上海人工智能实验室提出的以人为本的评估方法,特别引起了人们的注意。
评测现状堪忧
如今,在大模型这一领域,各类评测榜单层出不穷,模型们纷纷在榜单上力争高分。但这些分数虽然看似很高,却并未让人们对大模型在日常生活中能提供的实际便利产生深刻体会。2025年2月22日,全球开发者先锋大会的浦江AI生态论坛上,翟广涛教授指出,现行的以模型为基础的评估机制正面临数据泄露和性能限制这两个主要挑战。此外,大型模型虽然得分较高,但实际能力却有所欠缺。
“以人为本”思路提出
传统的模型测试多侧重于结果,对人的实际需求关注不够。但上海人工智能实验室的司南团队敢于突破,提出了以人为本的评估新法。他们设计的问题切合人的需求,让人与大型模型协作解决,再由人来对模型的辅助功能打分。这种方式既补充了客观评价的不足,也让评估结果更符合人的真实感受。这一思路的提出,就像是在黑暗中为大模型评测指明了方向。
“认知科学驱动”框架
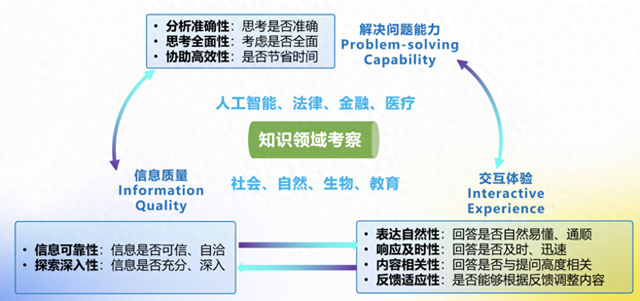
该评估体系以认知科学为基础,主要针对解决复杂问题的能力、信息的准确度以及用户交互感受这三个关键点,构建了一个适用于多种场景和领域的全面主观评价模型。在具体操作中,它模仿了学术研究和数据分析等实际需求,与用户协作完成作业。它通过收集用户反馈来评估模型的实际应用效果,为技术研发和产业应用提供科学依据,确保大型模型真正为人类服务。
验证评测实验设计
为了检验“以人为本”评估法的实际效果,司南团队精心挑选了评估对象,这些对象包括了当前普遍认可的几个模型,比如R1、GPT-o3-mini和Grok-3。他们邀请了有学术研究需求的研究生参与测试,针对学术研究中常遇到的问题,设计了涉及人工智能、法律、金融等八个领域的具体问题,并让他们与大型模型一起解决这些问题。这种设计能有效对大模型在学术研究实际应用中的实际效用进行精确判断。它有利于准确评估,确保大模型在真实学术研究场景中的实用性。
实验结果呈现
实验数据揭示了一些引人注目的情况。在考察精确度、思维广度和辅助效能这三个维度上,所有参与测试的模型表现相近。然而,每个模型都有其特别的优势,例如R1在生物和教育领域的问题处理上尤为出色;Grok-3在金融和自然科学方面表现更佳;GPT-o3-mini在社会领域的应用上尤为突出。这些研究让人们对不同模型的特点有了更清晰的了解。同时,这也说明,以人为中心的评估方式能有效地辨别各模型在实际应用中的效果。
评测意义与展望
以人为中心的评估体系与框架,让大型模型的测试更贴近人的需求,这对整个行业的发展起到了重要作用。这一理念不仅推动了大型模型研发更加关注人的实际需求,还推动了人工智能在各个领域的广泛应用。面向未来,随着评估体系的不断改进,我们坚信大型模型将成为人类日常生活和工作的得力助手。大家对这个问题有何看法?觉得大型模型会在哪个领域最先显现出明显优势?欢迎在评论区留言,同时记得点赞并转发这篇文章!



